DDGClassifier#
- class skfda.ml.classification.DDGClassifier(*, multivariate_classifier=None, depth_method=None)[source]#
Generalized depth-versus-depth (DD) classifier for functional data.
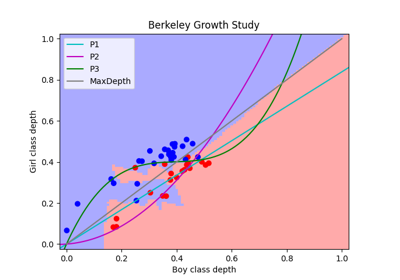
This classifier builds an interface around the DDGTransfomer. The transformer takes a list of k depths and performs the following map [1]:
\[\begin{split}\mathcal{X} &\rightarrow \mathbb{R}^G \\ x &\rightarrow \textbf{d} = (D_1^1(x), D_1^2(x),...,D_g^k(x))\end{split}\]Where \(D_i^j(x)\) is the depth of the point \(x\) with respect to the data in the \(i\)-th group using the \(j\)-th depth of the provided list. Note that \(\mathcal{X}\) is possibly multivariate, that is, \(\mathcal{X} = \mathcal{X}_1 \times ... \times \mathcal{X}_p\).
In the G dimensional space the classification is performed using a multivariate classifer.
- Parameters:
depth_method (Depth[Input] | Sequence[Tuple[str, Depth[Input]]] | None) – The depth class or sequence of depths to use when calculating the depth of a test sample in a class. See the documentation of the depths module for a list of available depths. By default it is ModifiedBandDepth.
multivariate_classifier (ClassifierMixin[NDArrayFloat, NDArrayInt] | None) – The multivariate classifier to use in the DDG-plot.
Examples
Firstly, we will import and split the Berkeley Growth Study dataset
>>> from skfda.datasets import fetch_growth >>> from sklearn.model_selection import train_test_split
>>> dataset = fetch_growth() >>> fd = dataset['data'] >>> y = dataset['target'] >>> X_train, X_test, y_train, y_test = train_test_split( ... fd, y, test_size=0.25, stratify=y, random_state=0)
>>> from skfda.exploratory.depth import ( ... ModifiedBandDepth, ... IntegratedDepth, ... ) >>> from sklearn.neighbors import KNeighborsClassifier
We will fit a DDG-classifier using KNN
>>> from skfda.ml.classification import DDGClassifier >>> clf = DDGClassifier( ... depth_method=ModifiedBandDepth(), ... multivariate_classifier=KNeighborsClassifier(), ... ) >>> clf.fit(X_train, y_train) DDGClassifier(...)
We can predict the class of new samples
>>> clf.predict(X_test) array([ 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1])
Finally, we calculate the mean accuracy for the test data
>>> clf.score(X_test, y_test) 0.875
It is also possible to use several depth functions to increase the number of features available to the classifier
>>> clf = DDGClassifier( ... depth_method=[ ... ("mbd", ModifiedBandDepth()), ... ("id", IntegratedDepth()), ... ], ... multivariate_classifier=KNeighborsClassifier(), ... ) >>> clf.fit(X_train, y_train) DDGClassifier(...) >>> clf.predict(X_test) array([ 1, 1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 1, 1]) >>> clf.score(X_test, y_test) 0.875
See also
DDClassifierMaximumDepthClassifier_ddg_transformerReferences
Methods
fit(X, y)Fit the model using X as training data and y as target values.
Get metadata routing of this object.
get_params([deep])Get parameters for this estimator.
predict(X)Predict the class labels for the provided data.
score(X, y[, sample_weight])Return accuracy on provided data and labels.
set_params(**params)Set the parameters of this estimator.
set_score_request(*[, sample_weight])Configure whether metadata should be requested to be passed to the
scoremethod.- fit(X, y)[source]#
Fit the model using X as training data and y as target values.
- Parameters:
X (Input) – FDataGrid with the training data.
y (Target) – Target values of shape = (n_samples).
- Returns:
self
- Return type:
DDGClassifier[Input, Target]
- get_metadata_routing()#
Get metadata routing of this object.
Please check User Guide on how the routing mechanism works.
- Returns:
routing – A
MetadataRequestencapsulating routing information.- Return type:
MetadataRequest
- predict(X)[source]#
Predict the class labels for the provided data.
- Parameters:
X (Input) – FDataGrid with the test samples.
- Returns:
- Array of shape (n_samples) with class labels
for each data sample.
- Return type:
Target
- score(X, y, sample_weight=None)[source]#
Return accuracy on provided data and labels.
In multi-label classification, this is the subset accuracy which is a harsh metric since you require for each sample that each label set be correctly predicted.
- Parameters:
X (array-like of shape (n_samples, n_features)) – Test samples.
y (array-like of shape (n_samples,) or (n_samples, n_outputs)) – True labels for X.
sample_weight (array-like of shape (n_samples,), default=None) – Sample weights.
- Returns:
score – Mean accuracy of
self.predict(X)w.r.t. y.- Return type:
- set_params(**params)[source]#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
**params (dict) – Estimator parameters.
- Returns:
self – Estimator instance.
- Return type:
estimator instance
- set_score_request(*, sample_weight='$UNCHANGED$')#
Configure whether metadata should be requested to be passed to the
scoremethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
sample_weight (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
sample_weightparameter inscore.self (DDGClassifier)
- Returns:
self – The updated object.
- Return type: