fetch_phoneme#
- skfda.datasets.fetch_phoneme(*, return_X_y: Literal[False] = False, as_frame: bool = False) Bunch[source]#
- skfda.datasets.fetch_phoneme(*, return_X_y: Literal[True], as_frame: Literal[False] = False) Tuple[FDataGrid, ndarray[Any, dtype[int64]]]
- skfda.datasets.fetch_phoneme(*, return_X_y: Literal[True], as_frame: Literal[True]) Tuple[DataFrame, Series]
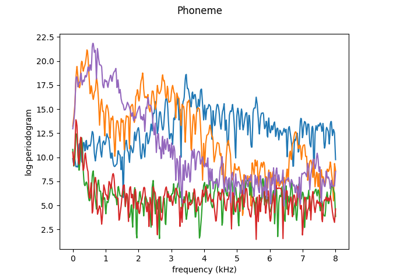
Load the phoneme dataset.
The data is obtained from the R package ‘ElemStatLearn’, which takes it from the dataset in https://web.stanford.edu/~hastie/ElemStatLearn/.
These data arose from a collaboration between Andreas Buja, Werner Stuetzle and Martin Maechler, and it is used as an illustration in the paper on Penalized Discriminant Analysis by Hastie, Buja and Tibshirani (1995).
The data were extracted from the TIMIT database (TIMIT Acoustic-Phonetic Continuous Speech Corpus, NTIS, US Dept of Commerce) which is a widely used resource for research in speech recognition. A dataset was formed by selecting five phonemes for classification based on digitized speech from this database. phonemes are transcribed as follows: “sh” as in “she”, “dcl” as in “dark”, “iy” as the vowel in “she”, “aa” as the vowel in “dark”, and “ao” as the first vowel in “water”. From continuous speech of 50 male speakers, 4509 speech frames of 32 msec duration were selected, approximately 2 examples of each phoneme from each speaker. Each speech frame is represented by 512 samples at a 16kHz sampling rate, and each frame represents one of the above five phonemes. The breakdown of the 4509 speech frames into phoneme frequencies is as follows:
aa
ao
dcl
iy
sh
695
1022
757
1163
872
From each speech frame, a log-periodogram was computed, which is one of several widely used methods for casting speech data in a form suitable for speech recognition. Thus the data used in what follows consist of 4509 log-periodograms of length 256, with known class (phoneme) memberships.
The data contain curves sampled at 256 points, a response variable, and a column labelled “speaker” identifying the different speakers.
References
Hastie, Trevor; Buja, Andreas; Tibshirani, Robert. Penalized Discriminant Analysis. Ann. Statist. 23 (1995), no. 1, 73–102. doi:10.1214/aos/1176324456. https://projecteuclid.org/euclid.aos/1176324456
- Parameters:
return_X_y – Return only the data and target as a tuple.
as_frame – Return the data in a Pandas Dataframe or Series.
Examples using skfda.datasets.fetch_phoneme#

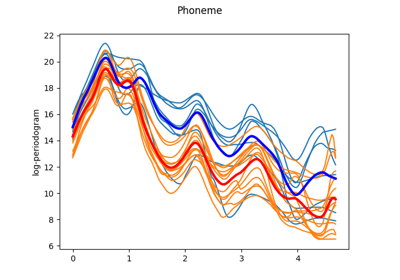
Voice signals: smoothing, registration, and classification