r2_score#
- skfda.misc.scoring.r2_score(y_true, y_pred, *, sample_weight=None, multioutput='uniform_average')[source]#
- skfda.misc.scoring.r2_score(y_true, y_pred, *, sample_weight=None, multioutput='uniform_average')
- skfda.misc.scoring.r2_score(y_true: DataType, y_pred: DataType, *, sample_weight: NDArrayFloat | None = None, multioutput: Literal['uniform_average'] = 'uniform_average') float
- skfda.misc.scoring.r2_score(y_true: DataType, y_pred: DataType, *, sample_weight: NDArrayFloat | None = None, multioutput: Literal['raw_values']) DataType
R^2 score for
FData.With \(y\_true = (X_1, X_2, ..., X_n)\) being the real values, \(t\_pred = (\hat{X}_1, \hat{X}_2, ..., \hat{X}_n)\) being the estimated and \(sample\_weight = (w_1, w_2, ..., w_n)\), the score is calculated as
\[R^2(y\_true, y\_pred)(t) = 1 - \frac{\sum_{i=1}^n w_i (X_i(t) - \hat{X}_i(t))^2} {\sum_{i=1}^n w_i (X_i(t) - Mean(y\_true, sample\_weight)(t))^2}\]where \(Mean\) is a weighted mean.
For \(y\_true\) and \(y\_pred\) of type
FDataGrid, \(R^2\) is also aFDataGridobject with the same grid points.If multioutput = ‘raw_values’, the function \(R^2\) is returned. Otherwise, if multioutput = ‘uniform_average’, the mean of \(R^2\) is calculated:
\[mean(R^2) = \frac{1}{V}\int_{D} R^2(t) dt\]where \(D\) is the function domain and \(V\) the volume of that domain.
For
FDataBasisonly ‘uniform_average’ is available.If \(y\_true\) and \(y\_pred\) are numpy arrays, sklearn function is called.
- Parameters:
y_true – Correct target values.
y_pred – Estimated values.
sample_weight – Sample weights. By default, uniform weights are taken.
multioutput – Defines format of the return.
- Returns:
R2 score
If multioutput = ‘uniform_average’ or \(y\_pred\) and \(y\_true\) are
FDataBasisobjects, float is returned.If both \(y\_pred\) and \(y\_true\) are
FDataGridobjects and multioutput = ‘raw_values’,FDataGridis returned.If both \(y\_pred\) and \(y\_true\) are ndarray and multioutput = ‘raw_values’, ndarray.
Examples using skfda.misc.scoring.r2_score#
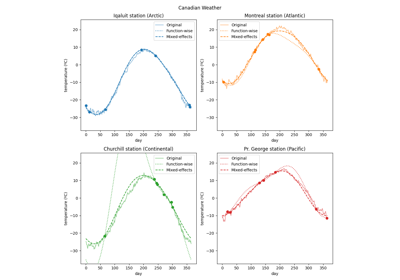
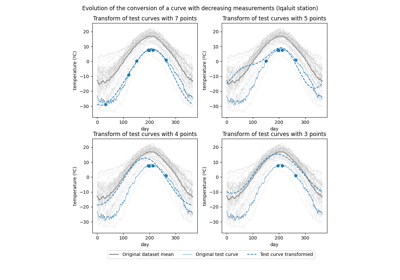
Mixed effects model for irregular data: robustness of the conversion by decimation