fetch_growth#
- skfda.datasets.fetch_growth(*, return_X_y: Literal[False] = False, as_frame: bool = False) Bunch[source]#
- skfda.datasets.fetch_growth(*, return_X_y: Literal[True], as_frame: Literal[False] = False) Tuple[FDataGrid, ndarray[Any, dtype[int64]]]
- skfda.datasets.fetch_growth(*, return_X_y: Literal[True], as_frame: Literal[True]) Tuple[DataFrame, Series]
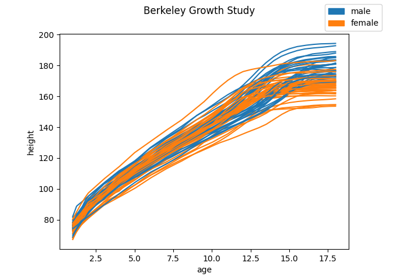
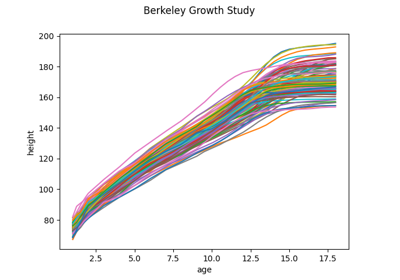
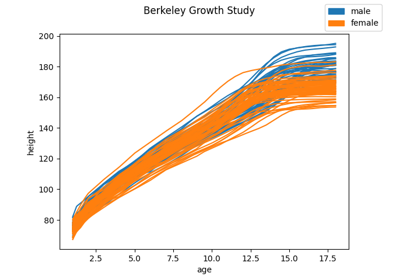
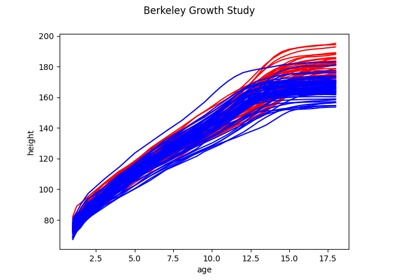
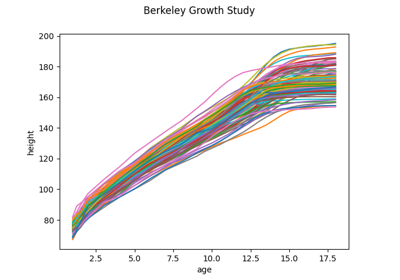
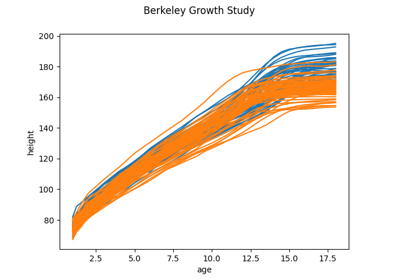
Load the Berkeley Growth Study dataset.
The data is obtained from the R package ‘fda’, which takes it from the Berkeley Growth Study.
The Berkeley Growth Study (Tuddenham and Snyder, 1954) recorded the heights of 54 girls and 39 boys between the ages of 1 and 18 years. Heights were measured at 31 ages for each child, and the standard error of these measurements was about 3mm, tending to be larger in early childhood and lower in later years.
References
Tuddenham, R. D., and Snyder, M. M. (1954) “Physical growth of California boys and girls from birth to age 18”, University of California Publications in Child Development, 1, 183-364.
- Parameters:
return_X_y – Return only the data and target as a tuple.
as_frame – Return the data in a Pandas Dataframe or Series.