Note
Go to the end to download the full example code. or to run this example in your browser via Binder
Mixed effects model for irregular data: robustness of the conversion by decimation#
This example converts irregular data to a basis representation using a mixed effects model and checks the robustness of the method by fitting the model with decreasing number of measurement points per curve.
# Author: Pablo Cuesta Sierra
# License: MIT
# sphinx_gallery_thumbnail_number = -1
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from skfda import FDataIrregular
from skfda.datasets import fetch_weather, irregular_sample
from skfda.misc.scoring import mean_squared_error, r2_score
from skfda.representation.basis import FourierBasis
from skfda.representation.conversion import EMMixedEffectsConverter
For this example, we are going to check the robustness of the mixed effects method for converting irregular data to basis representation by removing some measurement points from the test and train sets and comparing the resulting conversions.
The temperatures from the Canadian weather dataset are used to generate the irregular data. We use a Fourier basis due to the periodic nature of the data.
fd_temperatures = fetch_weather().data.coordinates[0]
basis = FourierBasis(n_basis=5, domain_range=fd_temperatures.domain_range)
We plot the original data and the basis functions.
fig = plt.figure(figsize=(10, 4))
axes = plt.subplot(1, 2, 1)
fd_temperatures.plot(axes=axes)
ylim = axes.get_ylim()
xlabel = axes.get_xlabel()
plt.title(fd_temperatures.dataset_name)
axes = plt.subplot(1, 2, 2)
basis.plot(axes=axes)
axes.set_xlabel(xlabel)
plt.title("Basis functions")
plt.suptitle("")
plt.show()

We split the data into train and test sets:
random_state = np.random.RandomState(seed=13627798)
train_original, test_original = train_test_split(
fd_temperatures,
test_size=0.3,
random_state=random_state,
)
Then, we create datasets with decreasing number of measurement points per curve, by removing measurement points from the previous dataset iteratively.
n_points_list = [365, 40, 10, 7, 5, 4, 3]
train_irregular_datasets = {}
test_irregular_datasets = {}
current_train = train_original
current_test = test_original
for n_points in n_points_list:
current_train = irregular_sample(current_train, n_points, random_state)
current_test = irregular_sample(current_test, n_points, random_state)
train_irregular_datasets[n_points] = current_train
test_irregular_datasets[n_points] = current_test
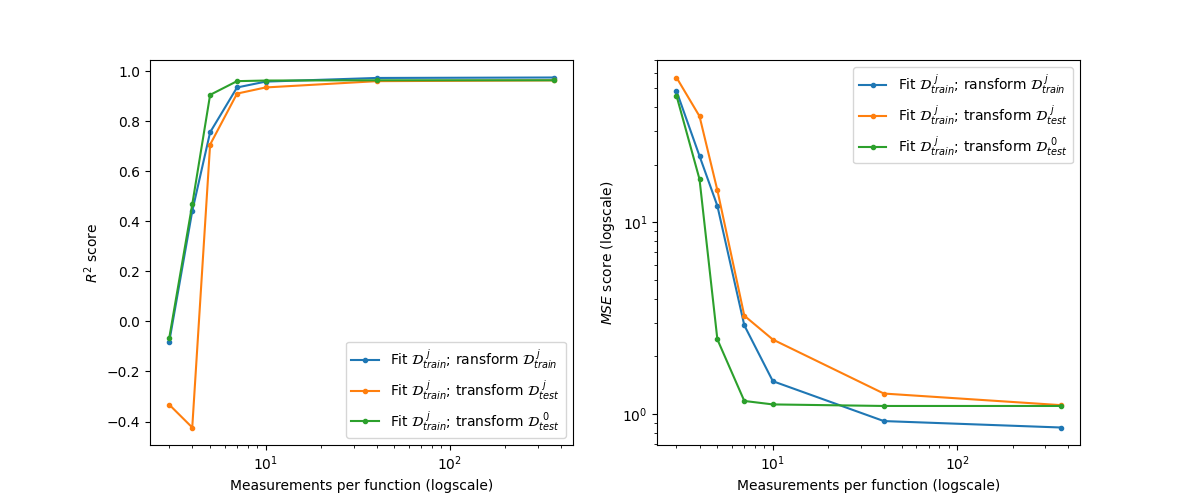
We convert the irregular data to basis representation and compute the scores. To do so, we fit the converter once per train set. After fitting the the converter with a train set that has \(k\) points per curve, we use it to transform that train set, the test set with \(k\) points per curve and the original test set with 365 points per curve.
score_functions = {"R^2": r2_score, "MSE": mean_squared_error}
converted_data = {"Train-sparse": {}, "Test-sparse": {}, "Test-original": {}}
scores = {
score_name: {
"n_points_per_curve": n_points_list,
**{data_name: [] for data_name in converted_data},
}
for score_name in score_functions
}
converter = EMMixedEffectsConverter(basis)
for n_points, train_irregular, test_irregular in zip(
n_points_list,
train_irregular_datasets.values(),
test_irregular_datasets.values(),
):
converter = converter.fit(train_irregular)
transformed = {
"Train-sparse": converter.transform(train_irregular),
"Test-sparse": converter.transform(test_irregular),
"Test-original": converter.transform(
FDataIrregular.from_fdatagrid(test_original),
),
}
# Store the converted data
for key, data in transformed.items():
converted_data[key][n_points] = data
# Calculate and store the scores
for score_name, score_fun in score_functions.items():
for key in converted_data:
scores[score_name][key].append(score_fun(
test_original if "Test" in key else train_original,
transformed[key].to_grid(test_original.grid_points),
))
Finally, we have the scores for the train and test sets with decreasing number of measurement points per curve.
for score_name in scores.keys():
print(f"{score_name} scores:")
print("-" * 62)
print((
pd.DataFrame(scores[score_name])
.round(3).set_index("n_points_per_curve").sort_index()
), end="\n\n\n")
R^2 scores:
--------------------------------------------------------------
Train-sparse Test-sparse Test-original
n_points_per_curve
3 -0.082 -0.333 -0.067
4 0.440 -0.424 0.467
5 0.755 0.706 0.905
7 0.934 0.910 0.960
10 0.958 0.934 0.962
40 0.972 0.959 0.963
365 0.974 0.963 0.963
MSE scores:
--------------------------------------------------------------
Train-sparse Test-sparse Test-original
n_points_per_curve
3 48.384 56.913 45.796
4 22.180 35.746 16.788
5 12.190 14.699 2.454
7 2.905 3.262 1.172
10 1.486 2.449 1.124
40 0.921 1.281 1.104
365 0.852 1.115 1.104
Plot the scores.
plt.figure(figsize=(12, 5))
for i, (score_name, values) in enumerate(scores.items()):
df = (
pd.DataFrame(values)
.sort_values("n_points_per_curve").set_index("n_points_per_curve")
)
plt.subplot(1, 2, i + 1)
label_start = r"Fit $\mathcal{D}_{train}^{\ j}$; "
plt.plot(
df.index,
df["Train-sparse"],
label=label_start + r"ransform $\mathcal{D}_{train}^{\ j}$",
marker=".",
)
plt.plot(
df.index,
df["Test-sparse"],
label=label_start + r"transform $\mathcal{D}_{test}^{\ j}$",
marker=".",
)
plt.plot(
df.index,
df["Test-original"],
label=label_start + r"transform $\mathcal{D}_{test}^{\ 0}$",
marker=".",
)
if score_name == "MSE":
plt.yscale("log")
plt.ylabel(f"${score_name}$ score (logscale)")
else:
plt.ylabel(f"${score_name}$ score")
plt.xscale("log")
plt.xlabel(r"Measurements per function (logscale)")
plt.legend()
plt.plot()
Show the original curves along with the converted test curves for the conversions with 7, 5, 4 and 3 points per curve.
def plot_conversion_evolution(index: int):
plt.figure(figsize=(8, 8.5))
i = 0
for n_points_per_curve in n_points_list[3:]:
axes = plt.subplot(2, 2, i + 1)
i += 1
test_irregular_datasets[n_points_per_curve][index].scatter(
axes=axes, color="C0",
)
fd_temperatures.mean().plot(
axes=axes, color=[0.4] * 3, label="Original dataset mean",
)
fd_temperatures.plot(
axes=axes, color=[0.7] * 3, linewidth=0.2,
)
test_original[index].plot(
axes=axes, color="C0", linewidth=0.65, label="Original test curve",
)
converted_data["Test-sparse"][n_points_per_curve][index].plot(
axes=axes,
color="C0",
linestyle="--",
label=f"Test curve transformed",
)
plt.title(f"Transform of test curves with {n_points_per_curve} points")
plt.ylim(ylim)
plt.suptitle(
"Evolution of the conversion of a curve with decreasing measurements "
f"({test_original.sample_names[index]} station)"
)
# Add common legend at the bottom:
handles, labels = plt.gca().get_legend_handles_labels()
plt.tight_layout(h_pad=0, rect=[0, 0.1, 1, 1])
plt.legend(
handles=handles,
loc="lower center",
ncols=3,
bbox_to_anchor=(-.1, -0.3),
)
plt.show()
Toronto station’s temperature curve conversion evolution:
plot_conversion_evolution(index=7)

Iqaluit station’s temperature curve conversion evolution:
plot_conversion_evolution(index=8)

As can be seen in the figures, the fewer the measurements, the closer the converted curve is to the mean of the original dataset. This leads us to believe that when the amount of measurements is too low, the mixed-effects model is able to capture the general trend of the data, but it is not able to properly capture the individual variation of each curve.
Total running time of the script: (0 minutes 26.908 seconds)