Note
Go to the end to download the full example code. or to run this example in your browser via Binder
Exploring data#
Explores the Tecator data set by plotting the functional data and calculating means and derivatives.
# Author: Miguel Carbajo Berrocal
# License: MIT
import numpy as np
import skfda
In this example we are going to explore the functional properties of the
Tecator dataset. This dataset
measures the infrared absorbance spectrum of meat samples. The objective is
to predict the fat, water, and protein content of the samples.
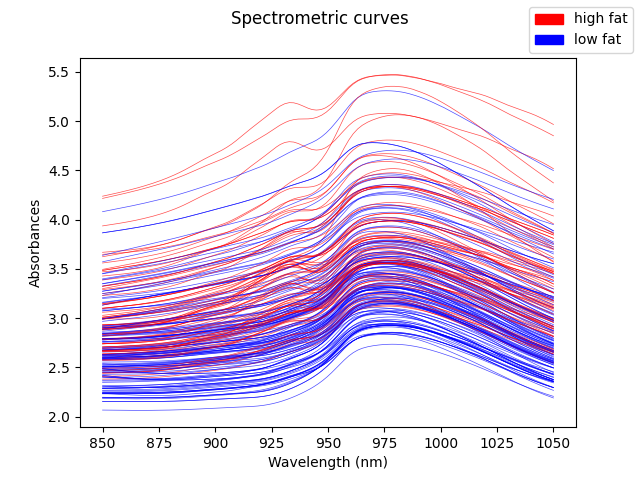
In this example we only want to discriminate between meat with less than 20% of fat, and meat with a higher fat content.
We will now plot in red samples containing less than 20% of fat and in blue the rest.
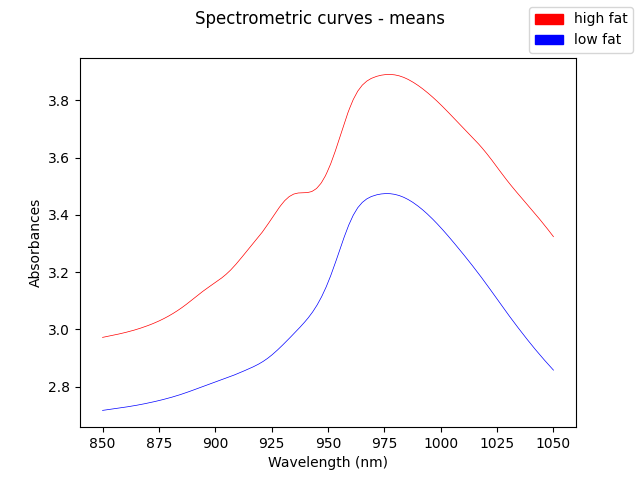
The means of each group are the following ones.
mean_low = skfda.exploratory.stats.mean(fd[low_fat])
mean_high = skfda.exploratory.stats.mean(fd[~low_fat])
means = mean_high.concatenate(mean_low)
means.dataset_name = f"{fd.dataset_name} - means"
means.plot(
group=['high fat', 'low fat'],
group_colors=colors,
linewidth=0.5,
legend=True,
)
<Figure size 640x480 with 1 Axes>
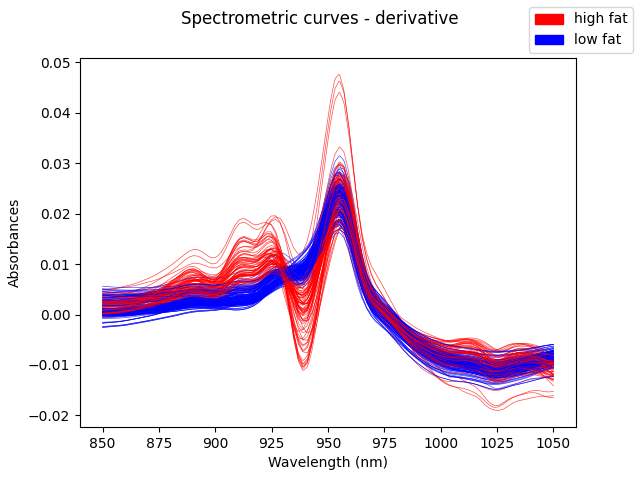
In this dataset, the vertical shift in the original trajectories is not very significative for predicting the fat content. However, the shape of the curve is very relevant. We can observe that looking at the first and second derivatives.
The first derivative is shown below:
fdd = fd.derivative()
fdd.dataset_name = f"{fd.dataset_name} - derivative"
fig = fdd.plot(
group=labels,
group_colors=colors,
linewidth=0.5,
alpha=0.7,
legend=True,
)
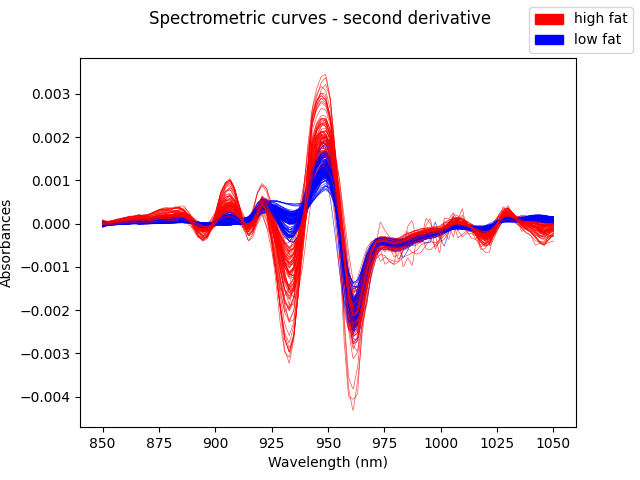
We now show the second derivative:
fdd = fd.derivative(order=2)
fdd.dataset_name = f"{fd.dataset_name} - second derivative"
fig = fdd.plot(
group=labels,
group_colors=colors,
linewidth=0.5,
alpha=0.7,
legend=True,
)
Total running time of the script: (0 minutes 2.032 seconds)